Day 2 — C++ on CPU
June 23, 2026 · Speakers: Sébastien Valat & Pierre Aubert (LAPP) · Marcel Vivargent Auditorium + satellite sites (including CINERI). Two distinct sessions: in the morning, C++ 17/20/23 on CPU; in the afternoon, advanced optimization (blocking & Pyramid). The hands-on lives in
GrayScott2026/day-2/— the GPU is not on today's menu.
Morning session — C++ 17/20/23 on CPU
1. The golden rule: measure first
No optimization is kept without a number. So the hands-on starts by building the measurement
tooling itself, in three steps (1-FirstPerformanceTest → 2-BenchmarkFunction →
3-FunctionTimer):
| Module | What you build | The lesson |
|---|---|---|
1-FirstPerformanceTest | a minimal timer.cpp | measuring is code too |
2-BenchmarkFunction | repetitions + statistics + pin_thread_to_core | a single measurement lies; pinning the thread stabilizes |
3-FunctionTimer | the reusable course FunctionTimer | the tool we keep for the whole school |
A detail that matters: pin_thread_to_core.cpp — without pinning, the scheduler walks the
thread from core to core and noise drowns the effect you are measuring.
2. The stencil — and why it is memory-bound
Gray-Scott's discrete Laplacian is a 3×3 stencil: each output point is a weighted sum of its nine neighbors.
A dozen flops for nine reads: arithmetic intensity is low. On Day 1's roofline this kernel lives under the sloped roof — it waits for memory, not compute. The whole day follows from this observation.
3. Data layout — the single biggest lever
Module 5-DataLayout: the same kernel with two memory walks (layout_efficient vs
layout_swap_axis). Memory is a 1D ribbon; the cache loads whole lines.
Walking the array in storage order feeds the cache; swapping the axes starves it on every access. Before any compute trick, fix the memory walk.
4. Vectorization — a conversation with the compiler
Module 6-Vectorization: no hand-written SIMD today — we let the compiler do it, provided
we hand it a clean loop (pure, contiguous, no aliasing; __restrict__ promises no aliasing).
| Target | Flags |
|---|---|
naive_gray_scott_O3 | -O3 |
autovec_gray_scott_O3 | -O3 -march=native -mtune=native -ftree-vectorize -funroll-loops |
-march=native unlocks the widest SIMD of the CPU (AVX2 → ×8 floats); the
autovectorization3x3 module specializes the kernel for the 3×3 stencil. Check what the
compiler actually did: make helpoption lists the hands-on build variants.
5. Assembling the simulation
Modules 9-Simulation (the assembled solver, from very_naive to autovec),
10-FullHDSimulation (scaling to 1920×1080), 7-DataOutput (HDF5 output) and
8-ImagePlotting (image conversion):
time ./9-Simulation/autovec_gray_scott_O3 -n 10 -e 30 -r 1080 -c 1920
mkdir pics && time ./8-ImagePlotting/gray_scott_image -i output.h5 -o pics/
The Turing patterns appear — the visual reward of the day:

Frame produced by the course simulation — figure from the official material, © Pierre Aubert (LAPP).
Afternoon session — Advanced optimization: blocking & Pyramid
6. Blocking (cache tiling)
Module 14-Blocking. On a Full HD grid, sweeping whole rows overflows the cache: every value
is evicted before being reused. Blocking splits the domain into tiles sized for a cache
level, and finishes each tile before moving on.
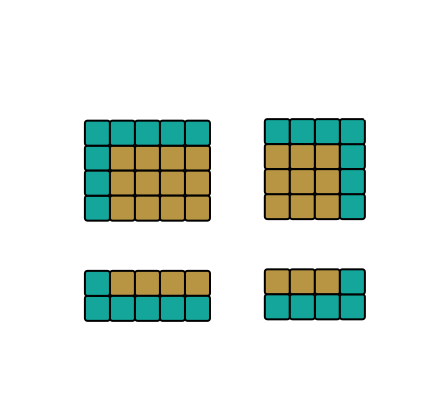
The course block decomposition: four families of blocks, each with its read halo — figure from the official material, © Pierre Aubert (LAPP).
7. The Pyramid — space-time tiling
Module 15-AdvancedBlocking, the summit of the day. Blocking tiles space; the Pyramid
tiles space and time: the cached tile absorbs several consecutive time steps (the halo
shrinks by one cell per step — hence the pyramid shape), and the anti-pyramid fills the
gaps between pyramids.
In the hands-on it is a real little library (151-PyramidLib): PyramidIterator,
PyramidIdx, AntiPyramidIdx — then 153-SimplePyramid plugs it into Gray-Scott.
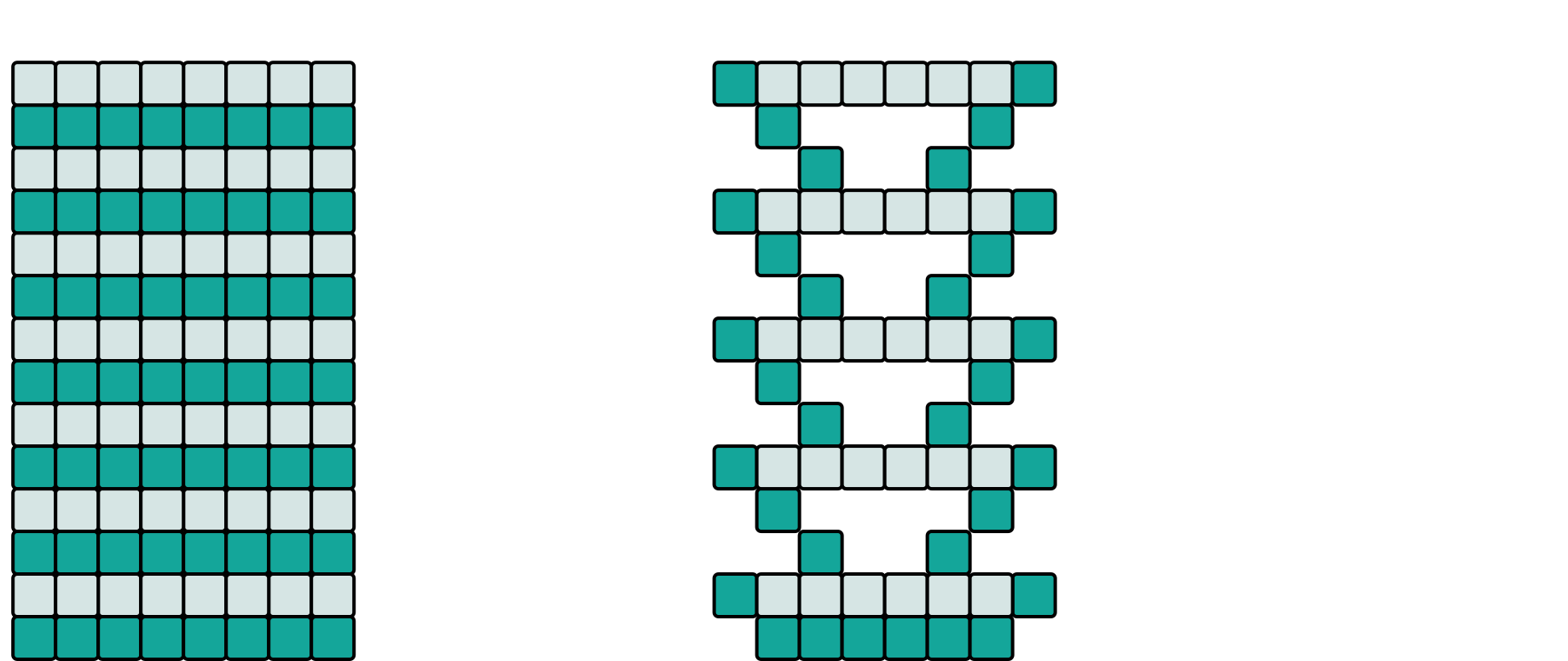
Left: naive iteration sweeps the whole domain at every step; right: the actual pyramid order from the course — figure from the official material, © Pierre Aubert (LAPP).
The folder
even ships auto-tuning: scriptFindBestPyramid.sh sweeps pyramid sizes and keeps the best
one for your machine. The day's final lesson: memory traffic is amortized across
iterations, not just across space.
The hands-on — GrayScott2026/day-2/
The environment is pinned with pixi (channels prefix.dev/phoenix + conda-forge — gcc,
cmake, HDF5, TBB, Phoenix libs), hence reproducible without a container:
cd GrayScott2026/day-2
pixi install # the whole toolchain, pinned
pixi shell
mkdir -p build && cd build
cmake .. $(phoenixcmake-config --cmake) && make -j$(nproc)
make plot_all # runs all the performance measurements
Official alternative: the course apptainer containers
(performancewithstencil_cpu_job). The repo's GPU/ folder exists but is not on today's
program; TBB/, 27-Deliverable and 29-DistributedComputing are exploited later in the
school.
On video — the official replays
Two episodes of the Gray Scott Thursdays (the school's webinar series) cover exactly today's material:
Sources & official material
- The online course (CPU chapters 1 → 20: measurement, layout, vectorization, blocking, Pyramid, valgrind/kcachegrind, OpenMP, TBB): cta-lapp.pages.in2p3.fr/COURS/PerformanceWithStencil
- The day's slides (PDF, school GitLab wiki): morning C++ lecture · blocking · simpler advanced blocking · gray-scott-blocking (June 2026)
- GitLab repositories: PerformanceWithStencil (hands-on code) · GrayScott2026 (the school)
- Video replays (YouTube): Gray Scott Thursdays · 2025 replays
- The environment: phoenix pixi channel · course containers · school website
Day 1 — Foundations
The vocabulary and principles. Optimizing means understanding how the hardware works and locating where time is lost.
Day 3 — Fortran on CPU
June 24, with Vincent Lafage: Fortran 2018 on CPU all day — the language of arrays, floating-point precision, the flags exercise, and the Gray-Scott solver in modern Fortran.