Jour 2 — C++ sur CPU
23 juin 2026 · Intervenants : Sébastien Valat & Pierre Aubert (LAPP) · Auditorium Marcel Vivargent + sites satellites (dont la CINERI). Deux sessions distinctes : le matin, C++ 17/20/23 sur CPU ; l'après-midi, l'optimisation avancée (blocking & Pyramide). Le TP du jour vit dans
GrayScott2026/day-2/— le GPU n'est pas concerné aujourd'hui.
Session du matin — C++ 17/20/23 sur CPU
1. La règle d'or : mesurer d'abord
On ne garde aucune optimisation sans chiffre. Le TP commence donc par construire l'outillage
de mesure lui-même, en trois crans (modules 1-FirstPerformanceTest → 2-BenchmarkFunction →
3-FunctionTimer) :
| Module | Ce qu'on construit | La leçon |
|---|---|---|
1-FirstPerformanceTest | un timer.cpp minimal | mesurer, c'est déjà du code |
2-BenchmarkFunction | répétitions + statistiques + pin_thread_to_core | une mesure isolée ment ; épingler le thread stabilise |
3-FunctionTimer | le FunctionTimer réutilisable du cours | l'outil qu'on gardera toute l'école |
Détail qui compte : pin_thread_to_core.cpp — sans épinglage, l'ordonnanceur balade le thread
de cœur en cœur et le bruit noie l'effet qu'on veut mesurer.
2. Le stencil — et pourquoi il est memory-bound
Le Laplacien discret de Gray-Scott est un stencil 3×3 : chaque point de sortie est une somme pondérée de ses neuf voisins.
Une douzaine de flops pour neuf lectures : l'intensité arithmétique est faible. Sur le roofline du Jour 1, ce noyau vit sous le toit incliné — il attend la mémoire, pas le calcul. Toute la journée découle de ce constat.
3. La disposition mémoire — le plus gros levier
Module 5-DataLayout : le même noyau, avec deux parcours mémoire (layout_efficient vs
layout_swap_axis). La mémoire est un ruban 1D ; le cache charge par lignes entières.
Parcourir le tableau dans l'ordre de stockage nourrit le cache ; inverser les axes le vide à chaque accès. Avant toute astuce de calcul, on règle le parcours mémoire.
4. La vectorisation — une conversation avec le compilateur
Module 6-Vectorization : on ne vectorise pas à la main aujourd'hui, on laisse le
compilateur le faire — à condition de lui donner une boucle propre (pure, contiguë, sans
aliasing ; __restrict__ promet l'absence d'aliasing).
| Cible | Flags |
|---|---|
naive_gray_scott_O3 | -O3 |
autovec_gray_scott_O3 | -O3 -march=native -mtune=native -ftree-vectorize -funroll-loops |
-march=native autorise le SIMD le plus large du CPU (AVX2 → ×8 floats) ; le module
autovectorization3x3 spécialise le noyau pour le stencil 3×3. Vérifier ce que le compilateur
a réellement fait : make helpoption liste les variantes de compilation du TP.
5. Assembler la simulation
Modules 9-Simulation (le solveur assemblé, du very_naive à l'autovec),
10-FullHDSimulation (passage à l'échelle 1920×1080), 7-DataOutput (écriture HDF5) et
8-ImagePlotting (conversion en images) :
time ./9-Simulation/autovec_gray_scott_O3 -n 10 -e 30 -r 1080 -c 1920
mkdir pics && time ./8-ImagePlotting/gray_scott_image -i output.h5 -o pics/
Les motifs de Turing apparaissent — la récompense visuelle de la journée :

Frame produite par la simulation du cours — figure du support officiel, © Pierre Aubert (LAPP).
Session de l'après-midi — Optimisation avancée : blocking & Pyramide
6. Le blocking (pavage du cache)
Module 14-Blocking. Sur une grille Full HD, balayer des lignes entières déborde le cache :
chaque valeur est évincée avant d'être réutilisée. Le blocking découpe le domaine en tuiles
dimensionnées pour un niveau de cache, et termine chaque tuile avant de passer à la suivante.
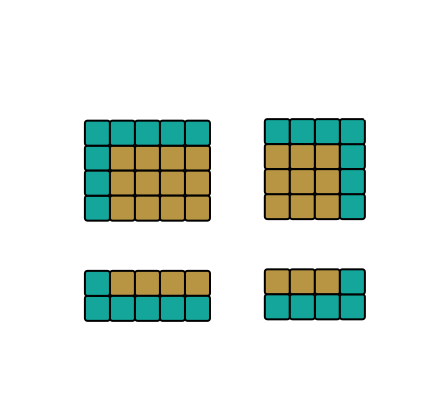
La décomposition en blocs du cours : quatre familles de blocs, chacun avec son halo de lecture — figure du support officiel, © Pierre Aubert (LAPP).
7. La Pyramide — pavage espace-temps
Module 15-AdvancedBlocking, le sommet de la journée. Le blocking pave l'espace ; la
Pyramide pave l'espace et le temps : la tuile chargée en cache encaisse plusieurs pas
de temps d'affilée (le halo rétrécit d'une cellule par pas — d'où la forme pyramidale), et
l'anti-pyramide comble les creux entre pyramides.
Dans le TP, c'est une vraie petite bibliothèque (151-PyramidLib) : PyramidIterator,
PyramidIdx, AntiPyramidIdx — puis 153-SimplePyramid branche le tout sur Gray-Scott.
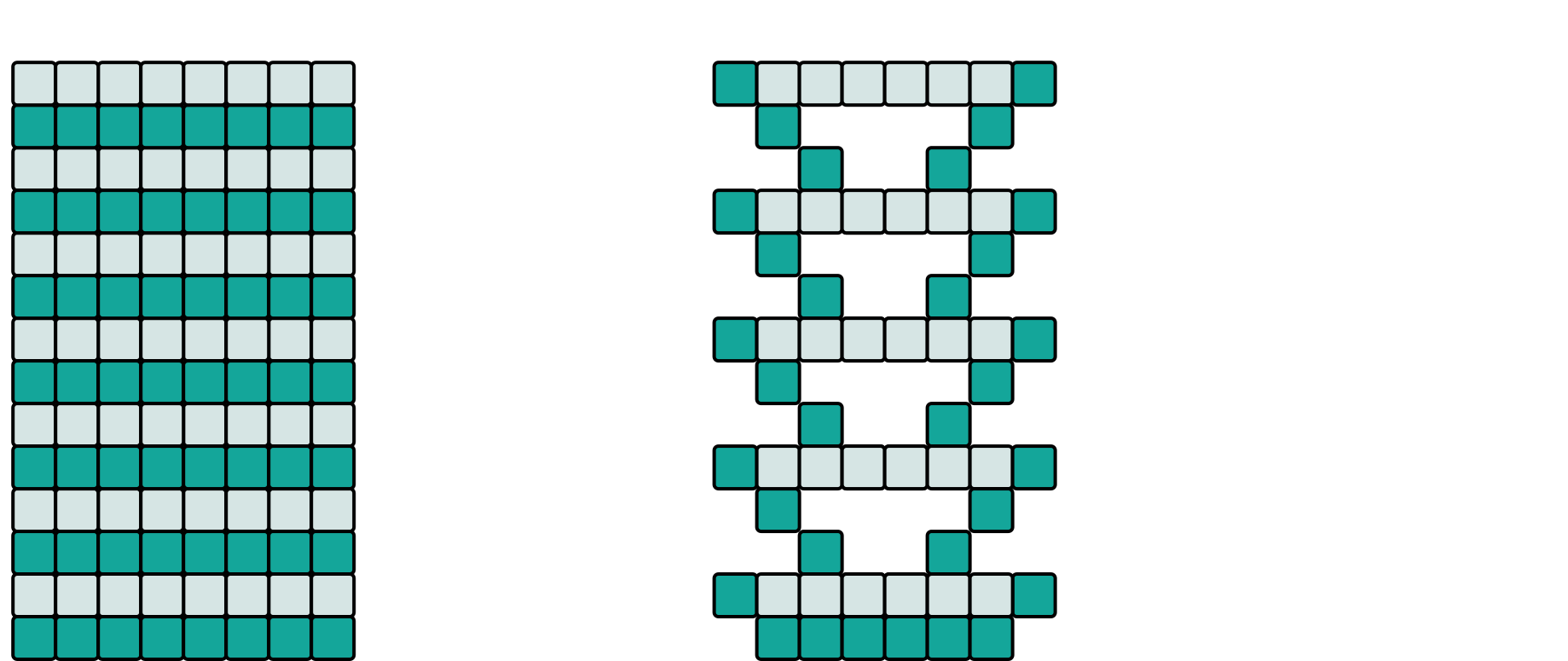
À gauche, l'itération naïve balaye tout le domaine à chaque pas ; à droite, l'ordre pyramidal réel du cours — figure du support officiel, © Pierre Aubert (LAPP).
Le dossier fournit même l'auto-tuning : scriptFindBestPyramid.sh balaie les tailles de
pyramide et retient la meilleure pour ta machine. La leçon finale de la journée : le trafic
mémoire s'amortit sur les itérations, pas seulement sur l'espace.
Le TP — GrayScott2026/day-2/
L'environnement est figé avec pixi (canaux prefix.dev/phoenix + conda-forge — gcc, cmake,
HDF5, TBB, libs Phoenix), donc reproductible sans conteneur :
cd GrayScott2026/day-2
pixi install # toute la chaîne d'outils, épinglée
pixi shell
mkdir -p build && cd build
cmake .. $(phoenixcmake-config --cmake) && make -j$(nproc)
make plot_all # lance toutes les mesures de performance
Alternative officielle : les conteneurs apptainer du cours
(performancewithstencil_cpu_job). Le dossier GPU/ du dépôt existe mais n'est pas au
programme du jour ; TBB/, 27-Deliverable et 29-DistributedComputing seront exploités plus
tard dans l'école.
En vidéo — les replays officiels
Deux épisodes des Gray Scott Thursdays (la série de webinaires de l'école) couvrent exactement la matière du jour :
Sources & matériel officiel
- Le cours en ligne (chapitres CPU 1 → 20 : mesure, layout, vectorisation, blocking, Pyramide, valgrind/kcachegrind, OpenMP, TBB) : cta-lapp.pages.in2p3.fr/COURS/PerformanceWithStencil
- Les slides du jour (PDF, wiki GitLab de l'école) : présentation C++ du matin · blocking · advanced blocking simplifié · gray-scott-blocking (juin 2026)
- Les dépôts GitLab : PerformanceWithStencil (code du TP) · GrayScott2026 (l'école)
- Replays vidéo (YouTube) : Gray Scott Thursdays · replays 2025
- L'environnement : canal pixi phoenix · conteneurs du cours · site de l'école
Jour 1 — Fondations
Le vocabulaire et les principes. Optimiser suppose de comprendre le fonctionnement du matériel et de localiser les pertes de temps.
Jour 3 — Fortran sur CPU
24 juin, avec Vincent Lafage : Fortran 2018 sur CPU toute la journée — le langage des tableaux, la précision flottante, l'exercice des flags, et le solveur Gray-Scott en Fortran moderne.