SenLand
SenLand — l'occupation des sols du Sénégal par deep learning
Un vrai projet IA, exécuté pour de vrai — entièrement sur un seul portable, avec les techniques apprises à la Gray Scott School (CINERI). Le même réseau de neurones cartographie l'occupation des sols — eau, cultures, forêt, bâti, mangroves — à partir d'images satellites libres. La question d'ingénierie qui structure tout le projet : faire tourner ce code d'abord sur le CPU, puis sur le GPU de la même machine, et comparer honnêtement les deux moteurs de calcul — leur architecture, la manière de les exploiter, leurs limites, et les résultats mesurés.
Le problème
Savoir où se trouvent les cultures, l'eau, les forêts et les villes — et comment cela change d'une année à l'autre — est une question nationale : agriculture, ressource en eau, urbanisation, climat. La cartographie manuelle ne passe pas à l'échelle d'un pays. Un réseau de neurones apprend à lire les images satellites et produit la carte automatiquement, partout, à la même résolution.
Le pipeline, de bout en bout
Quatre étapes : on lit les données ouvertes (imagerie + labels), on les découpe en petits patches, un U-Net segmente chaque patch, et on recompose la carte d'occupation des sols.
Les données (100 % libres)
Imagerie Sentinel-2 (cloudless, 10 m) alignée au pixel près avec les labels ESA WorldCover (10 m). Quatre zones aux paysages volontairement très différents, lues en direct depuis les serveurs publics — aucune donnée privée, aucun téléchargement massif.

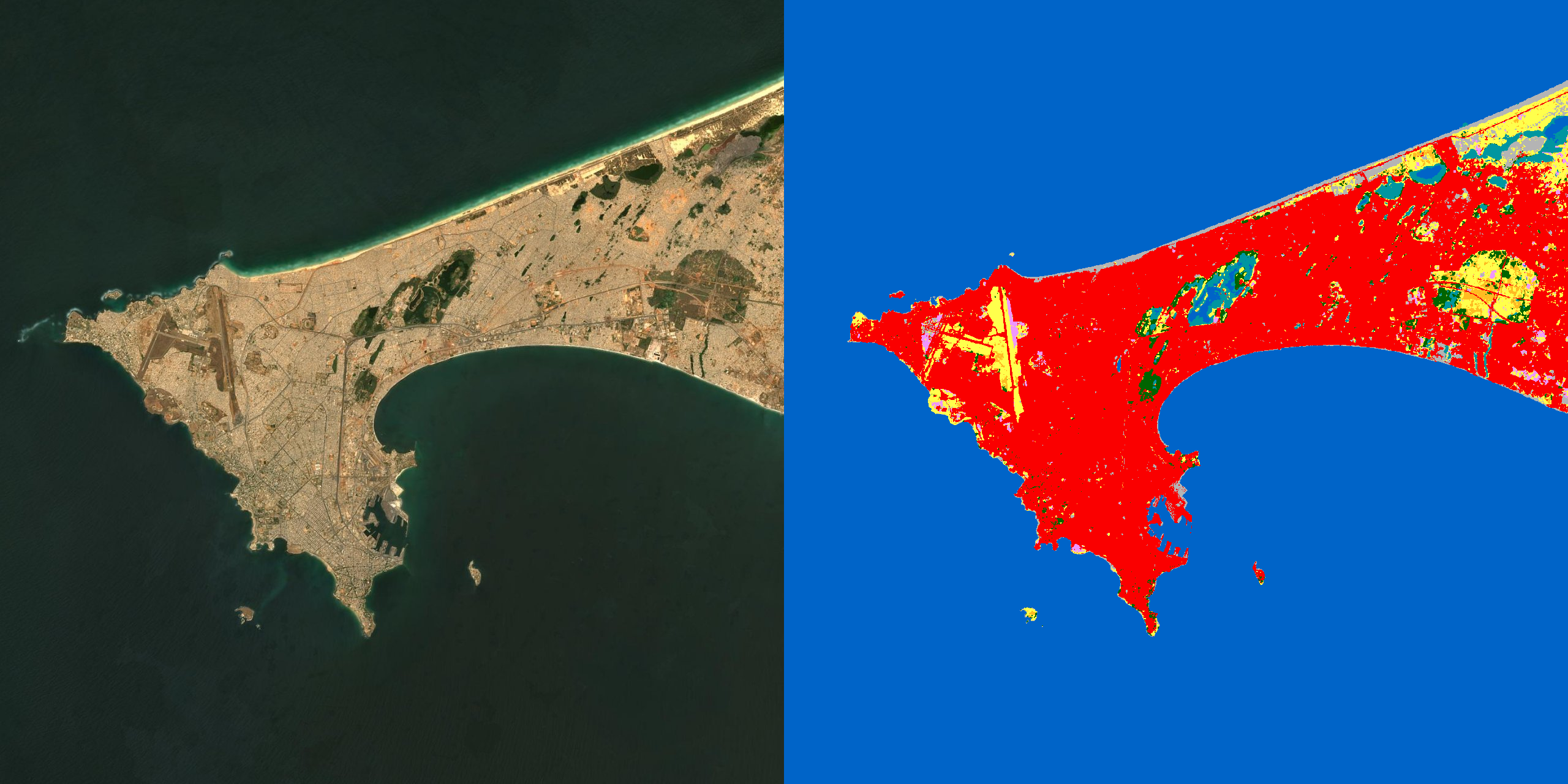

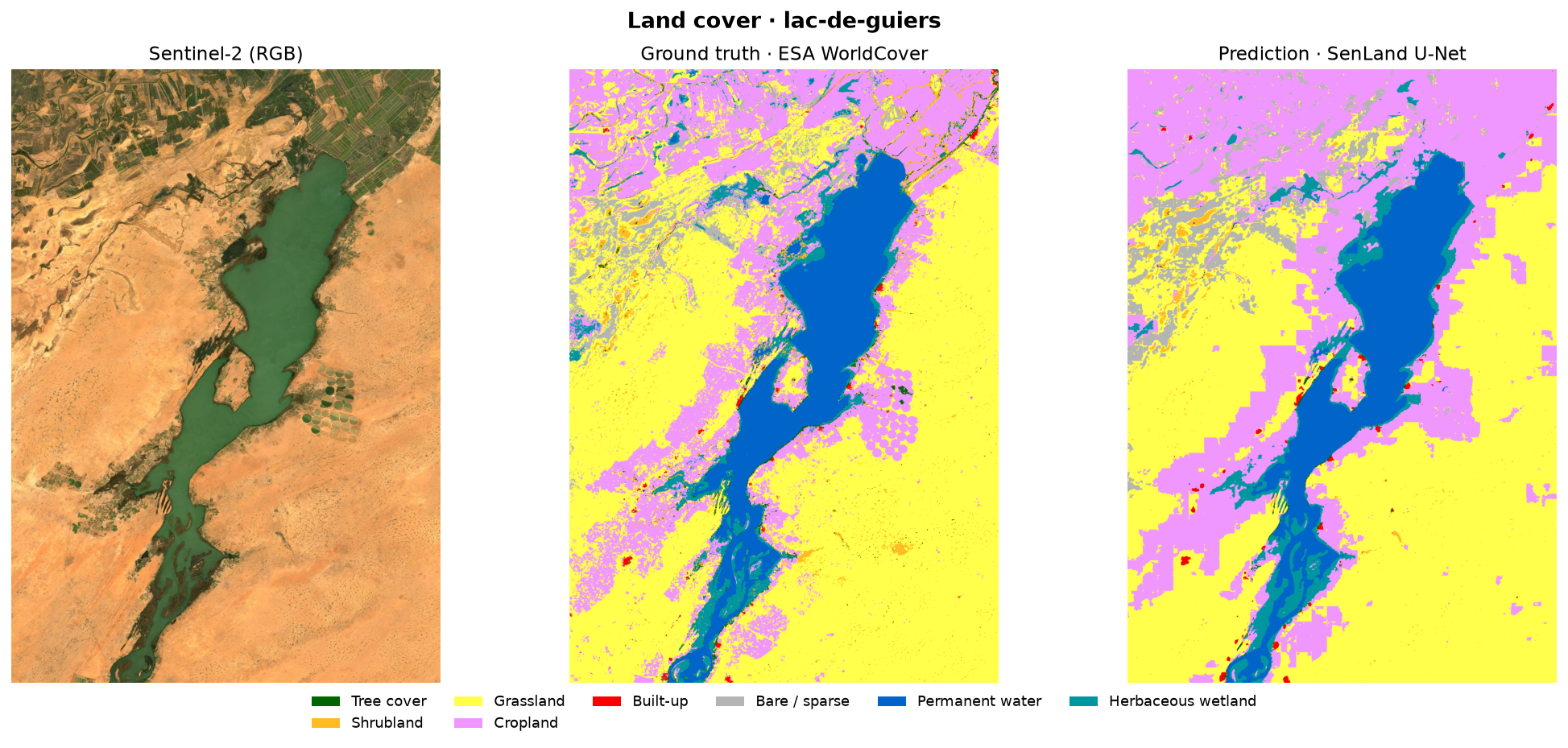
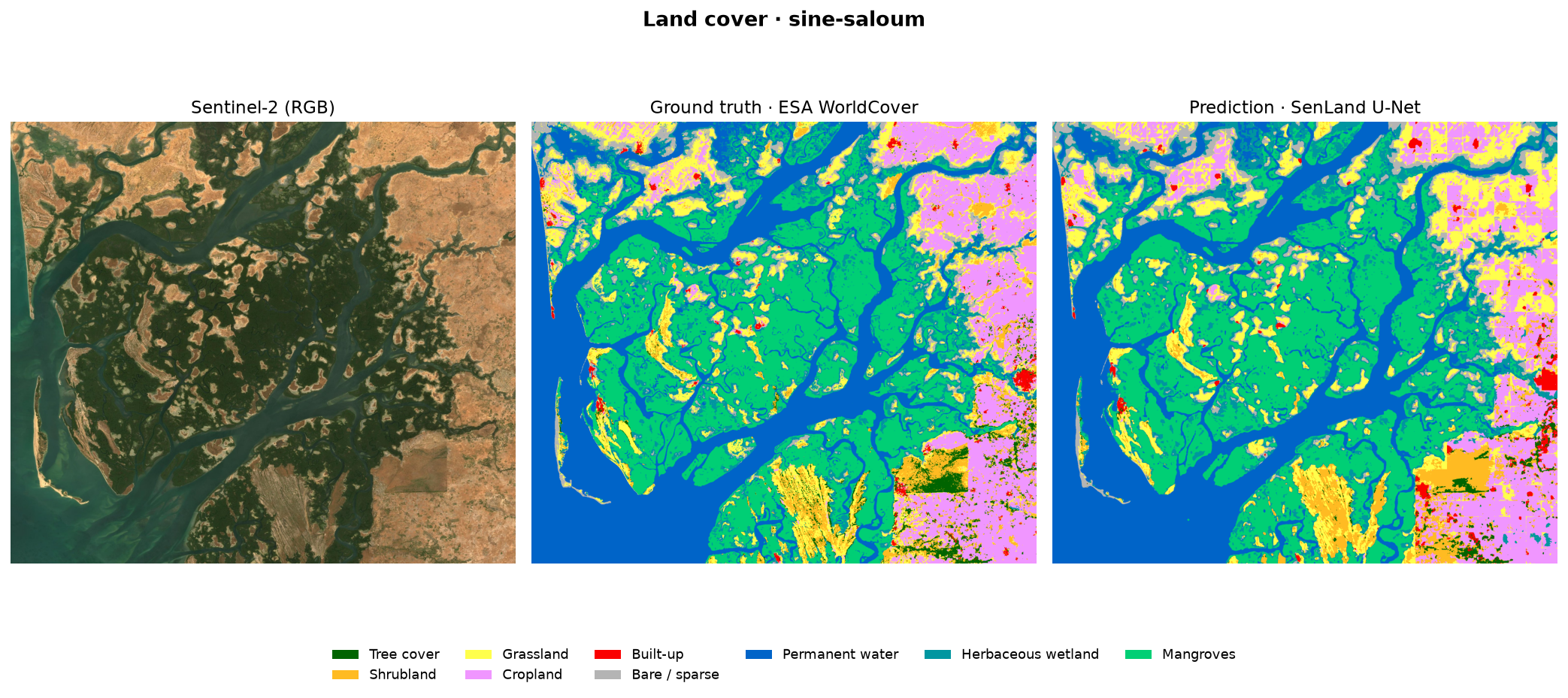
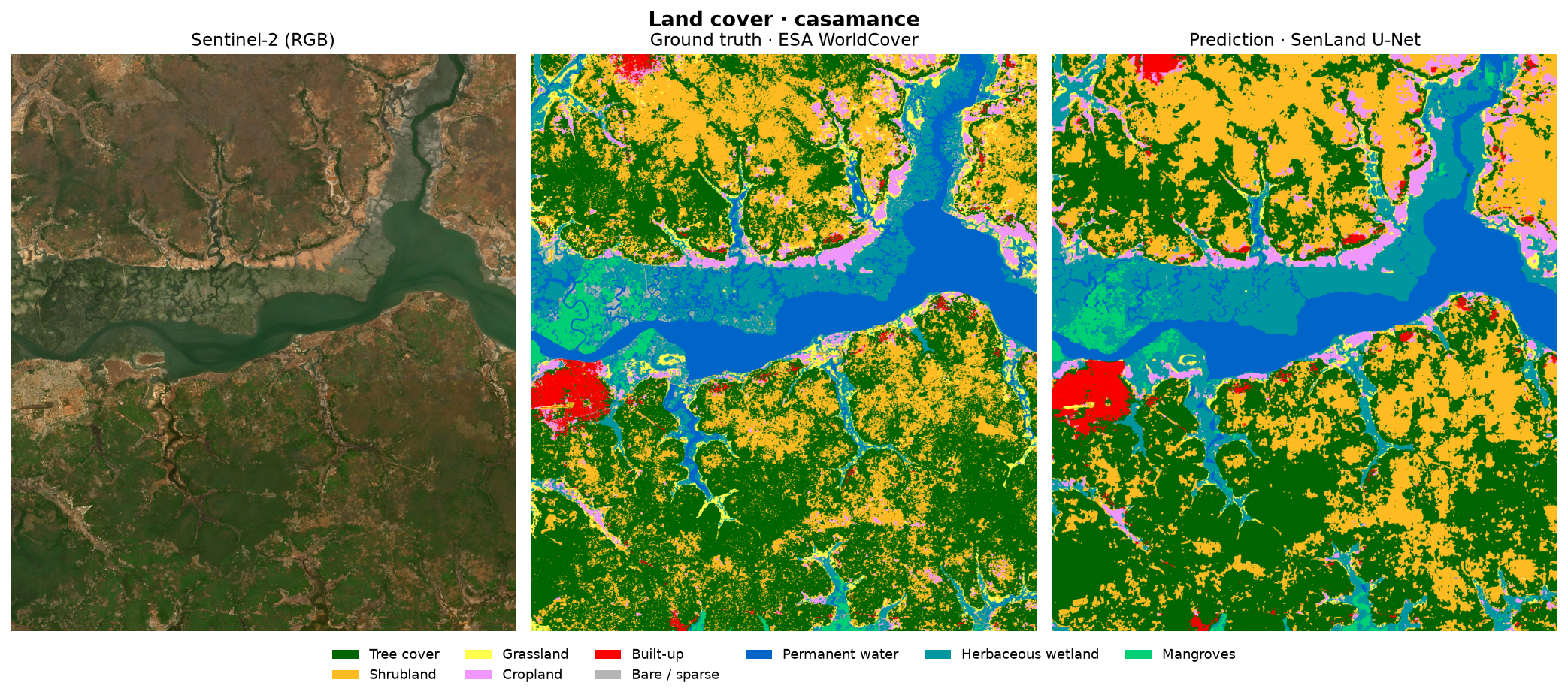
Résultats — les cartes
Pour chaque zone : l'image Sentinel-2, la vérité terrain (WorldCover) et la prédiction du modèle, côte à côte. Le lac, l'océan et les grandes structures agricoles sont fidèlement reconstitués.

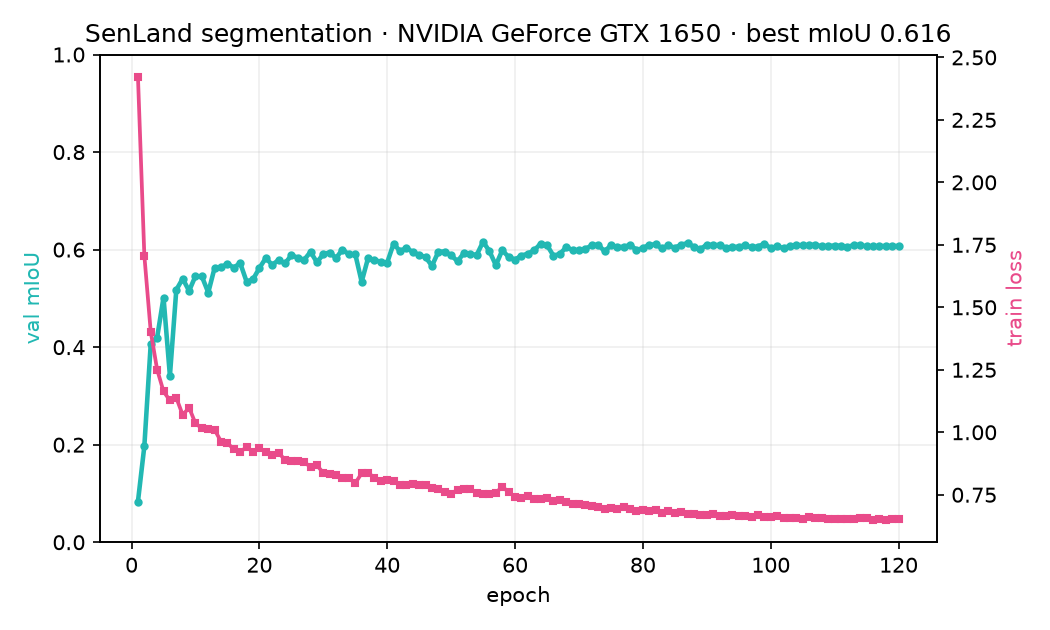
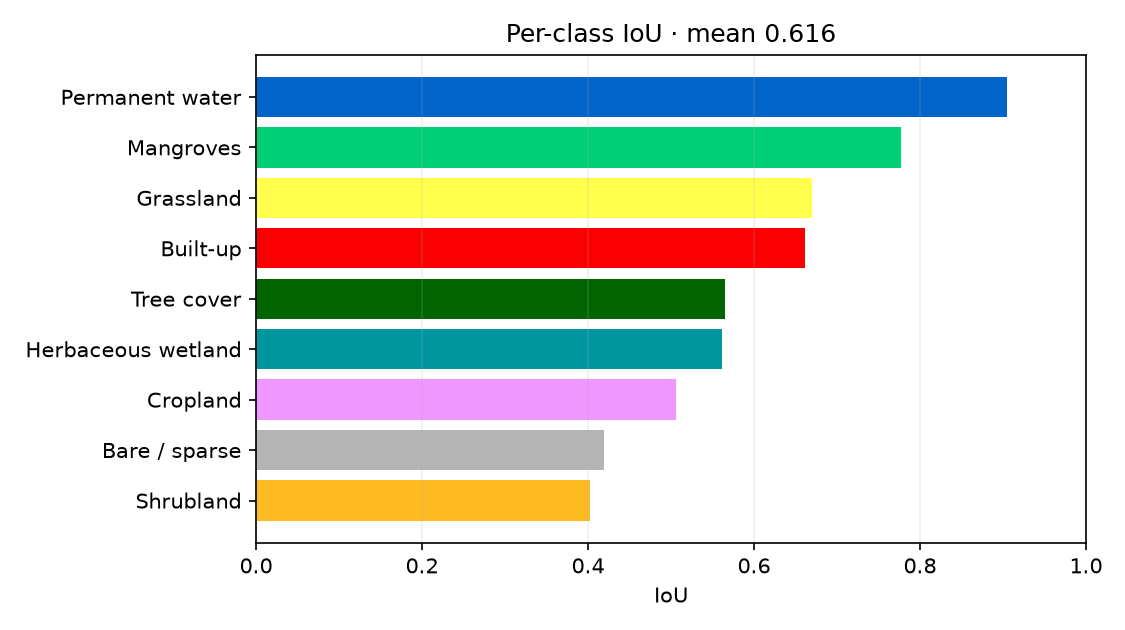
Métriques
La segmentation est évaluée sur un découpage spatial (zone de validation tenue à l'écart, pour une mesure honnête de la généralisation).
| Tâche | Métrique | Valeur |
|---|---|---|
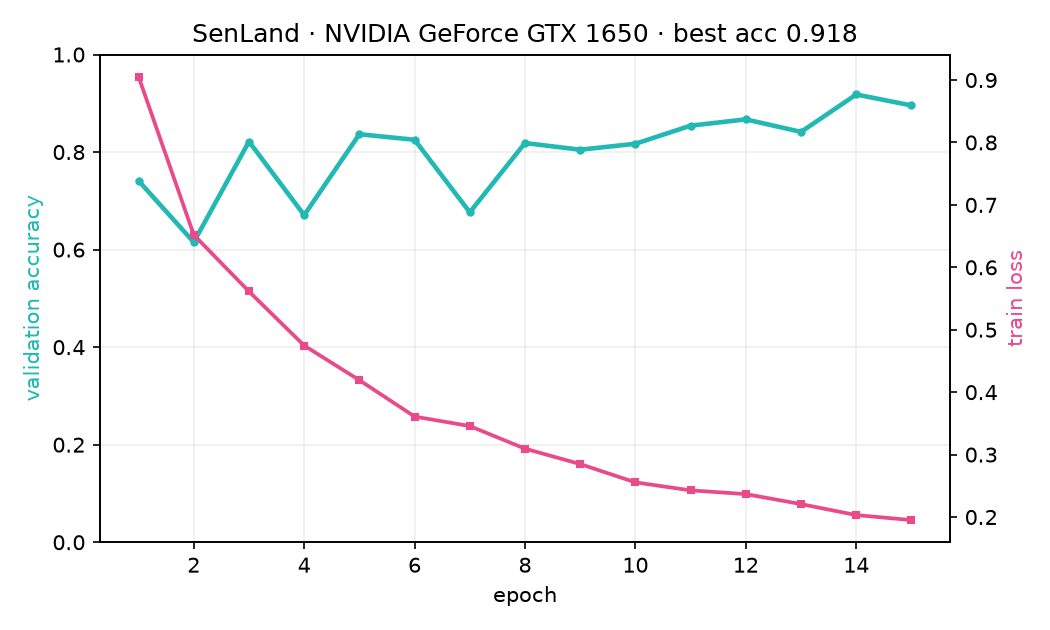
| Classification (EuroSAT, 10 classes, from scratch) | accuracy validation | 91,8 % |
| Segmentation (4 zones, découpage spatial) | mIoU | 0,62 |
En ajoutant le delta du Saloum au jeu d'entraînement, les mangroves passent de 3 % à 83 % d'IoU — la démonstration que la bonne donnée vaut mieux qu'un modèle plus gros.
L'architecture — un seul code, deux moteurs
Le modèle est un U-Net (encodeur ResNet-34) pour la segmentation, précédé d'un ResNet-18
pour l'échauffement de classification, le tout en PyTorch. Le cœur du projet reprend l'idée
de Kokkos vue au Jour 4 : un seul code source, deux backends. C'est exactement le même
code qui s'exécute sur le CPU ou sur le GPU — une couche d'introspection matérielle (hw.py)
choisit le périphérique et le déclare honnêtement dans chaque figure, jamais un run CPU
étiqueté « GPU ».
Sur CPU, le parallélisme passe par les threads intra-op OpenMP (Jour 1 / TBB) ; sur GPU, par le parallélisme massif SIMT des cœurs CUDA (Jour 2 / 3). Aucune ligne de science ne change : seul le débit d'itération change.
Sur CPU
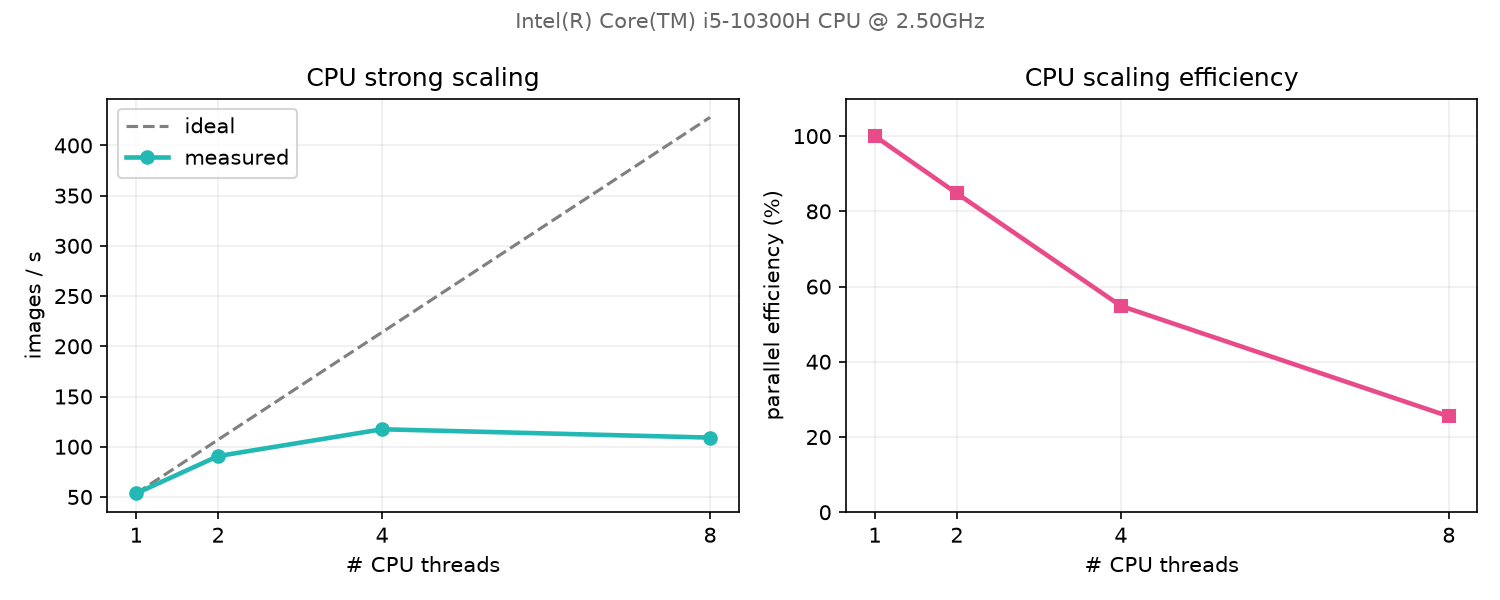
Pas de GPU requis : le même code exploite tous les cœurs via les threads OpenMP. Strong scaling mesuré sur le portable (Intel i5-10300H, 1 → 8 threads). L'efficacité retombe au-delà de 4 threads : la machine n'a que 4 cœurs physiques, l'HyperThreading n'aide pas le calcul dense.
- Avantages — disponible partout (aucun matériel spécialisé) ; beaucoup de RAM, idéal pour
l'I/O géo (lecture
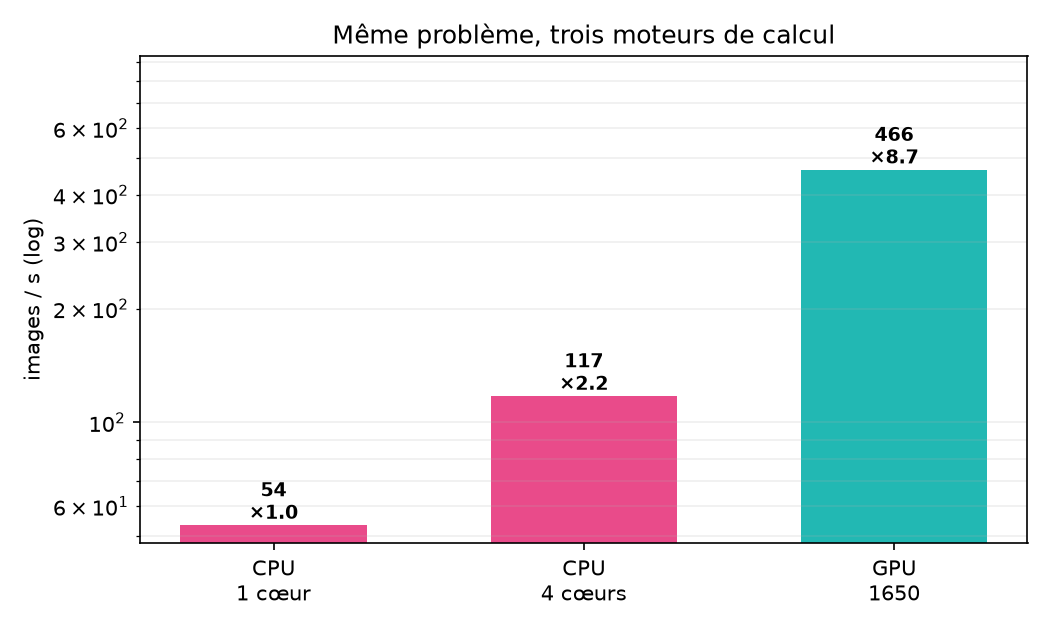
/vsicurlde Sentinel-2 + WorldCover) ; débogage simple et reproductible ; strong scaling réel (×2,2 de 1 à 4 cœurs, 54 → 117 img/s). - Limites — plafonne à 4 cœurs physiques (l'HyperThreading n'apporte rien : 117 → 109 img/s) ; ≈ 4× plus lent que le GPU modeste de la même machine ; une époque en ~25 s contre ~5 s sur GPU.
Mêmes poids, même qualité de modèle — uniquement plus lent. Le CPU produit exactement la même science, à un débit moindre.
Sur GPU
Le GPU applique un parallélisme massif (SIMT) : des milliers de cœurs CUDA traitent le batch d'un coup. Sur la GTX 1650 du portable, le débit atteint 466 img/s, l'itération devient fluide — ce qui a rendu possibles les entraînements longs (120 époques de segmentation).
- Avantages — ≈ ×4 plus rapide que le meilleur CPU, ×8,6 vs un seul cœur ; itération fluide (époque à 5,5 s) ; architecture taillée pour les convolutions denses — le SIMT colle au modèle.
- Limites — VRAM limitée (4 Go), qui contraint la taille de batch et de tuile ; la précision mixte (AMP fp16) diverge en NaN sur cette carte grand public — désactivée en local (une limite honnête) ; surcoût de transfert hôte→device.
Strictement le même modèle et la même précision finale que sur CPU — le GPU ne change pas le résultat, il le délivre ~4× plus vite. Le gain est entièrement du temps d'ingénieur récupéré.
Face-à-face — débit mesuré
Même problème, même code, trois moteurs de la même machine. Tout est mesuré ici, sur le portable — rien n'est projeté.
Le port JAX — comparer les frameworks, pas seulement les moteurs
Prolongement direct des Jours 5 et 7 de l'école (Python sur CPU, puis sur GPU) : la même
tâche de segmentation est réimplémentée en JAX/Flax (src/senland_jax/) pour comparer les
frameworks en plus des moteurs — mêmes zones du Sénégal, même métrique IoU. Le modèle est
un U-Net from scratch (GroupNorm, 7,8 M paramètres, sans pré-entraînement ImageNet) ; le
pas d'entraînement est une fonction pure compilée par jax.jit et différentiée par
jax.value_and_grad.
| Framework | Moteur | mIoU | Débit |
|---|---|---|---|
| PyTorch — U-Net ResNet-34, ImageNet | GPU GTX 1650 | 0,62 | 470 patch/s |
| JAX — U-Net GroupNorm, from scratch | GPU GTX 1650 | 0,57 | 211 patch/s |
| JAX — même modèle | CPU i5-10300H | — | 13 patch/s |
Lecture honnête de ces chiffres :
- mIoU 0,57 vs 0,62 — l'écart vient de l'encodeur pré-entraîné ImageNet côté PyTorch ; le modèle JAX apprend de zéro. Les IoU par classe restent très proches (eau permanente 0,90 vs 0,91, mangroves 0,77 vs 0,78).
- L'histoire « un code, deux moteurs » tient aussi en JAX : le même code jitté tourne
≈ ×16 plus vite sur GPU que sur CPU — ici via le placement de device (
JAX_PLATFORMS) plutôt quehw.py.
Même code JAX, placement du device via JAX_PLATFORMS — ≈ ×16 sur GPU.
Le benchmark équitable — modèle identique dans les deux frameworks
Comparer un ResNet-34 pré-entraîné à un petit U-Net maison n'est pas une course équitable.
scripts/bench_unet.py construit donc le U-Net strictement identique (GroupNorm, 11
classes) dans les deux frameworks et chronomètre le pas d'entraînement complet (forward +
CE+Dice + backward + AdamW) sur un batch résident en mémoire GPU — pour isoler le
framework/compilateur de l'architecture. GTX 1650, fp32 :
| Mode | batch 8 | batch 16 |
|---|---|---|
JAX — naïf (jit par pas) | 246 | — |
| PyTorch — eager | 334 | — |
PyTorch — torch.compile | 356 | 460 |
JAX — pas fusionnés (lax.fori_loop) | 371 | 463 |
(patch/s ; plus haut = mieux)
U-Net GroupNorm identique dans les deux frameworks, pas d'entraînement complet, GTX 1650 fp32.
Les enseignements :
- Le JAX naïf (un dispatch par pas) est le plus lent. Une fois ses vrais leviers activés —
jit,donate_argnums(réutilisation des buffers), entrées résidentes sur le device, et surtout la fusion des pas (lax.fori_loop: 20 pas pour le coût d'un dispatch) — JAX dépassetorch.compileà batch 8 (+4 %) et l'égale à batch 16. - À modèle identique, JAX bien réglé ≈ PyTorch bien réglé sur cette carte. L'écart de ~2× observé plus haut venait de l'architecture (ResNet-34 smp vs U-Net maison), pas du framework. L'avantage de XLA s'élargirait sur TPU, sur de plus gros batchs/modèles ou des graphes plus fusionnables — rien qu'un GPU grand public de 4 Go ne sollicite.
Piège de reproduction honnête :
jax[cuda12]et PyTorch épinglent des versions différentes denvidia-cudnn-cu12— dans un même venv, un seul des deux a le GPU à la fois. Utiliser deux environnements séparés.
Réalisé avec les techniques de la Gray Scott School
Chaque brique d'ingénierie de SenLand reprend une technique vue à la Gray Scott School (CINERI) et l'applique au deep learning. Le fil rouge — un seul code, CPU puis GPU — est l'idée même de Kokkos.
| Brique | Jour de l'école |
|---|---|
| Un seul code, deux backends | Jour 4 · Kokkos → ici hw.py (PyTorch) et JAX_PLATFORMS (JAX) |
| Frameworks & compilateurs | Jours 5 & 7 · Python/JAX — jit, XLA, fusion de pas (fori_loop) |
| CPU multicœur | Jour 1 · parallélisme + Jour 2 · TBB — mémoire partagée, strong scaling |
| GPU SIMT / CUDA | Jour 2 · GPU + Jour 3 · CUDA — parallélisme massif |
| Benchmark & timing | Jour 2 · workload fixe, débit img/s |
| Vectorisation / SIMD | Jour 1 + Jour 6 · EVE — analogue de la précision mixte (AMP) |
| Précision flottante | Jour 3 · fp32/fp16 — explique le NaN AMP sur GTX 1650 |
| I/O & données | Jour 2 · HDF5 → ici géo I/O Sentinel-2 / WorldCover |
| Conteneurs & repro | pixi / Apptainer — seeds fixes, expériences versionnées |
SenLand est un projet ouvert et reproductible : chaque chiffre de cette page est adossé à une figure committée dans le dépôt. Le code tourne sans GPU ; avec un GPU, tout va simplement ~4× plus vite.